Tabu search
salve a tutti! qualcuno potrebbe indirizzarmi per l'utilizzo del tabu search per la ricerca di max e min d una funzione? di teoria se ne trova tanta sul web, ma avrei bisogno di qualche esempio per capire come utilizzarlo. Spero qualcuno possa aiutarmi!!!!!
Risposte

"irelimax":
grazie il codice è molto chiaro. volevo chiederti 2 cose:
1) cos'è ceil((DIM_POP-2)/50)*36 quando definisci la TABU_TIME? non l'hai definita da nessuna parte nel codice
1. le funzioni ceil() e floor()... non le conosci, sono le funzioni intero superiore ed intero inferiore http://en.wikipedia.org/wiki/Floor_and_ ... _functions
comunque mi hai fatto notare una dimenticanza, il codice corretto è:
((int)ceil((DIM_POP-2)/50))*36
anche se c'è il casting implicito, meglio chiarire tutto

2)nella funzione add_tl non capisco se è stato un tuo errore o una mia incomprensione. alla funzione cp_chrom passi i parametri a ed f ma penso che li hai inseriti nell'ordine sbagliato. infatti nel caso in cui scrivi cp_chrom(n,&(tl->tabu_l[tl->tail].ch)) nella funzione add_tl copi il valore nella tabu list in P[0] il che deve essere al contrario. inoltre quando richiami cp_chrom(delete_al(AL),&(P[k])) copi P[k] nell'aspiration list il che deve essere il contrario come da teoria. se non sbaglio dovrei scrivere void cp_chrom(chrom* f,chrom* a)
hai ragione, sorry
allora è "copia chrom da $a$ in $f$" perciò:
void cp_chrom(chrom* a,chrom* f){
f->point[0]=a->point[0];
f->point[1]=a->point[1];
f->fit = a->fit;
}poi c'è un palese errore nel punto della Tabu_Search():
P[k]=FP[it_FP];
la copia non è diretta ma tramite la funzione sopra, perciò:
cp_chrom(&FP[it_FP],&P[k]);
ah, se non è chiaro $FP[]$, cioè la "last population", sta per FirstPopulation o FlinstonesPopulation, scegli te
Se non lo hai notato non ho ancora sistemato l'inserimento degli elementi nella Tabu_List, cioè tutte le funzioni e le strutture dati sono a posto e funzionanti, la cosa da sistemare è l'algoritmo Tabu_Serch() con alcune condizioni da sistemare come quelle già dette (TABU_TIME, ecc..), l'aspiration criteria (che forse non serve), ma manca la condizione di inserimento degli elementi Tabu...nel codice attuale avrai ancora un elemento come nello pseudo-codice che si parlava in settimane.
Per sistemare questo ultimo problema, devi rispondere alle domande dell'ultimo post... Poi non dovrebbe esserci altro, se non un dubbio sull'iteratore $k$ se farlo partire da $1$ o $0$ questo lo sistemiamo ad algoritmo funzionante.
Un'ultima cosa, hai pensato a cosa fare se la Distanza euclidea è $0$? (questo comporta la modifica di $k$).
Per intanto, se il codice ti è chiaro non lo commento
Il numero di iterazioni del GA lo inserisco da tastiera quindi non fisso un valore costante come per esempio hai fatto tu nel TS definendo la costante ITERATOR. l'argoritmo che uso per l'ordinamento è uno dei più semplici possibili e si appoggia sull'uso di una variabile temporale per non perdere nessun valore durante lo scambio. l'algoritmo è il seguente:
la distanza l'ho cosi definita:
non capisco a cosa ti riferisci quando dici che bisogna modificare k
chrom temp; //temp chrome to use in sorting
for(int i=0;i<DIM_POP-1;i++)
{
for(int j=0;j<DIM_POP-1-i;j++) //sorting the given set according to fitness
{
if(popcurrent[j+1].fit>popcurrent[j].fit)
{
temp=popcurrent[j+1];
popcurrent[j+1]=popcurrent[j];
popcurrent[j]=temp;
}
}
}
la distanza l'ho cosi definita:
boolean DISTANCE(chrom* b,chrom* d)
{
return (boolean) (sqrt(pow(b.point[0]-d.point[0],2)+pow(b.point[1]-d.point[1],2))<R)
}non capisco a cosa ti riferisci quando dici che bisogna modificare k
Allora per l'ordinamento a dire il vero non capisco come possa funzionarti il codice... sarà l'ora... me lo guardo meglio domani...
Intanto ti dico subito che è piuttosto inefficiente, come penso tu abbia già intuito.
Se non vuoi usare algoritmi troppo complicati, almeno è meglio usarne uno di poche righe ma almeno efficiente in certi aspetti (il tuo è $O(n^2)$ sempre, qualunque sia il dato in input). Perciò perchè non usare un più stabile insertion-sort:
prova con questo, non sarà sicuramento il più efficiente, ma il molti casi fa il suo dovere, fai come credi poi
per k è dovuta al fatto che in posizione P[0] ci sia il fit migliore sempre o meno, e se calcolando la distanza con P[0] e l'elemento tabu che è lo stesso cromosoma risulta $0
Appena sarà "funzionante" mi servirà vedere una stampa della popolazione prima e dopo la TS così vedo le perturbazioni fatte nel vettore.
PS: per curiosità, questo algoritmo ti servirà per qualche corso in università?
EDIT:
ho ricalcolato la complessità, il tuo algoritmo di ordinamento è $O(n^3)$
Intanto ti dico subito che è piuttosto inefficiente, come penso tu abbia già intuito.
Se non vuoi usare algoritmi troppo complicati, almeno è meglio usarne uno di poche righe ma almeno efficiente in certi aspetti (il tuo è $O(n^2)$ sempre, qualunque sia il dato in input). Perciò perchè non usare un più stabile insertion-sort:
void insertion_fit_sort(chrom* pop){
chrom* temp = malloc(sizeof(chrom));
if(!temp) exit(0);
int i,j;
i=1;
j=0;
while(i<DIM_POP){
cp_chrom(&pop[i],temp);
j = i-1;
while (j >= 0 && pop[j].fit > temp->fit){
cp_chrom(&pop[j],&pop[j+1]);
j = j-1;
}
cp_chrom(temp,&pop[j+1]);
i++;
}
free(temp);
}prova con questo, non sarà sicuramento il più efficiente, ma il molti casi fa il suo dovere, fai come credi poi
per k è dovuta al fatto che in posizione P[0] ci sia il fit migliore sempre o meno, e se calcolando la distanza con P[0] e l'elemento tabu che è lo stesso cromosoma risulta $0
Appena sarà "funzionante" mi servirà vedere una stampa della popolazione prima e dopo la TS così vedo le perturbazioni fatte nel vettore.
PS: per curiosità, questo algoritmo ti servirà per qualche corso in università?
EDIT:
ho ricalcolato la complessità, il tuo algoritmo di ordinamento è $O(n^3)$
Allora ti ho sistemato alcune cose:
- aggiunto funzione deinit() per deallocare AL e TL visto che fai più iterazioni di GA
- inizializzato k=0 invece che 1, in questo modo c'è da aggiungere una condizione da DISTANCE che sia anche >0 (motivo vedi altro post)
- corretto un errore nel codice
a parte alcune cose da sistemare che sono solo dei parametri, volevo farti notare come chiamare correttamente la funzione. Visto che abbiamo deciso che "last population" sta per la popolazione (di iterazione) precedente, la prima chiamata a Tabu_searcg userà una copia della popolazione corrente, le chiamate delle iterazioni di GA successive dipendono se hai allocato population[] in modo statico o dinamico, nel secondo vaso basta porre FP=P, cioè uno scambio di puntatori, nel primo caso bisogna fare una copia 1:1 con ogni cromosoma. Intanto questo è per iniziare la prima iterazione, per le successive vedi te come sistemare il codice con il resto:
ti ho scritto questo così puoi testare almeno se funziona il codice (per essere corretto mancano alcune cose), intanto siamo posto così (per oggi penso di non avere altro tempo, forse domani)
- aggiunto funzione deinit() per deallocare AL e TL visto che fai più iterazioni di GA
- inizializzato k=0 invece che 1, in questo modo c'è da aggiungere una condizione da DISTANCE che sia anche >0 (motivo vedi altro post)
- corretto un errore nel codice
boolean DISTANCE(chrom* b,chrom* d){
float g = sqrt(pow(b.point[0]-d.point[0],2)+pow(b.point[1]-d.point[1],2));
return (boolean) (g>0&g<R);
}
void deinit(aspiration_list* al, tabu_list* tl){
free(al->aspiration_l);
free(al);
free(tl->tabu_l);
free(tl);
}
void Tabu_Search(chrom* P,chrom* FP){
int TABU_TIME = ceil((DIM_POP-2)/50)*36;
int ITERATION = 4*DIM_POP;
int DIM_TL = 3*DIM_POP;
int k = 0;
int I = 0;
int f = 0;
int it_FP = DIM_POP-1;
tabu_list* TL = init_tl(DIM_TL);
if(TL==NULL){
exit(0);
}
//la dimensione conta poco della AL, non la si riempirà mai, perchè è limitata dal TABU_TIME=0
aspiration_list* AL = init_al(DIM_TL);
if(AL==NULL){
exit(0);
}
add_tl(&(P[0]),TL,TABU_TIME);
while(I<ITERATION){
//gli elementi a TIME_TABU=0 possono essere solo singoli elementi per iterazione, cioè può essere UNO solo.
//perciò basta controllare solo l'elemento da più tempo in lista, corrispondente all'elemento in testa
if(time_zero(TL)){
add_al(delete_tl(TL),AL);
}
k=0;;
/* interatore sulla popolazione P, */
while(k<DIM_POP){
//navigazione in TABU_LIST in ordine di inserimento decrescente
f=TL->head;
while(f!=TL->tail){
//scrivere la funzione boolean DISTANCE(chrom*,chrom*)
if(DISTANCE(&(P[k]),&(TL->tabu_l[f].ch))){
if(emptyp_al(AL)){ //se la AL è vuota
cp_chrom(&FP[it_FP],&(P[k]));
it_FP--;
/* sostituire il cromosoma ella popolazione attuale con quello di fitness minore degli antenati */
/* (per ogni iterazione si decresce di indice)*/
}
else{
cp_chrom(delete_al(AL),&(P[k]));
}
}
f=next_tl(f,TL);
}
k++;
}
//si diminuisce il tabu time per ogni elemento
time_zero_TT(TL);
I++;
}
deinit(AL,TL);
}a parte alcune cose da sistemare che sono solo dei parametri, volevo farti notare come chiamare correttamente la funzione. Visto che abbiamo deciso che "last population" sta per la popolazione (di iterazione) precedente, la prima chiamata a Tabu_searcg userà una copia della popolazione corrente, le chiamate delle iterazioni di GA successive dipendono se hai allocato population[] in modo statico o dinamico, nel secondo vaso basta porre FP=P, cioè uno scambio di puntatori, nel primo caso bisogna fare una copia 1:1 con ogni cromosoma. Intanto questo è per iniziare la prima iterazione, per le successive vedi te come sistemare il codice con il resto:
int i = 0;
chrom* FP = malloc(sizeof(chrom)*DIM_POP);
if(iteration_GA==1){
while(i<DIM_POP){
cp_chrom(P[i],FP[i]);
i++;
}
}
Tabu_Search(P,FP);
ti ho scritto questo così puoi testare almeno se funziona il codice (per essere corretto mancano alcune cose), intanto siamo posto così (per oggi penso di non avere altro tempo, forse domani)
vediamo di continuare un po'.
Già che ci sono vorrei capire un po' come hai costruito tutto l'algoritmo così valuto un po' come trattare la TS (abbiamo tutte le strutture dati basta solo modellarla a dovere).
- creai una popolazione random su un intervallo fissato
- la ordini per fitness (1)
- la fitness è la quota della funzione
- fai una perturbazione dei cromosomi con crossover
- controlli che la mutazione sia stabilizzata per una rate fissato
- riordini (2) per fitness
- qua entrerebbe in gioco la tabu_search
ora i punti che non mi sono chiari
- li riordini per l'elite? (1)
- (2) lo usi solo per trovare il best-fitness da introdurre nella Tabu_list?
- che ne fai della popolazione dopo la TS?
Già che ci sono vorrei capire un po' come hai costruito tutto l'algoritmo così valuto un po' come trattare la TS (abbiamo tutte le strutture dati basta solo modellarla a dovere).
- creai una popolazione random su un intervallo fissato
- la ordini per fitness (1)
- la fitness è la quota della funzione
- fai una perturbazione dei cromosomi con crossover
- controlli che la mutazione sia stabilizzata per una rate fissato
- riordini (2) per fitness
- qua entrerebbe in gioco la tabu_search
ora i punti che non mi sono chiari
- li riordini per l'elite? (1)
- (2) lo usi solo per trovare il best-fitness da introdurre nella Tabu_list?
- che ne fai della popolazione dopo la TS?
(1) La riordino per l'elite esatto. infatti fissata la costante ELITIST pari a 5, una volta ordinata la popolazione conservo i primi 5 cromosomi migliori (cioè con fitness migliore) applicando a tutti gli altri crossover e mutation. ovviamente questi primi 5 cambieranno ad ogni iterazione poichè, applicando crossover e mutation, si fa in modo di trasformare i cromosomi che ci sono nelle posizioni più in basso, qualcuno dei quali potrebbe quindi diventare migliore di uno (o più) dei primi 5 cromosomi dell'elite e quindi salire di posizione grazie all'ordinamento introdotto per ogni ciclo.
(2) esatto! lo uso solo per trovare il best-fitness da introdurre nella TL.
visto che siamo partiti per inserire il TS nel ciclo principale in modo da farlo rannare ad ogni ciclo subito dopo la mutation, esso dovrebbe copiare la popolazione P nella population e passarla al GA per fare nuovamente tutte le operazioni descritte da te passo passo.
(2) esatto! lo uso solo per trovare il best-fitness da introdurre nella TL.
visto che siamo partiti per inserire il TS nel ciclo principale in modo da farlo rannare ad ogni ciclo subito dopo la mutation, esso dovrebbe copiare la popolazione P nella population e passarla al GA per fare nuovamente tutte le operazioni descritte da te passo passo.
Ciao,
bhe questa non è una mia scelta, deve essere così, se no non ha molto senso usare la ricerca locale...
ok, e questo conferma ciò che ho pensato, la tabu search descritta in quel testo non va bene. Poi abbiamo interpretato male (ho intrpretato) il testo. Capita spesso se al descrizione è fatta in poche righe.
Ho in mente altro per risolvere, quello che cambia è quando dice "after finding tabu" si modifica la popolazione corrente con gli elementi della aspiration list, quest'ultimi sono creati dalla Tabu_search con un qualche metodologia che guardo ora e non si basano sempre sulla popolazione.
Se dovessimo utilizzare la popolazione P come base per trovare una soluzione con miglio fitness (o distanza) non troveremmo nulla di migliore, perchè in posizione P[0] c'è giò la quota massima possibile. E' chiaro cosa non va in questo modello?
Perciò quello che cambia:
- aspiration list saranno salvati nuovi punti trovati con la TS
- la popolazione P è modificato DOPO la TS con il metodo già descritto negli altri post
- la last population corrisponde a P, la popolazione corrente corrsiponde a P modificata con AL
così ha anche più senso
Altre cose, i vari parametri del GA (elite, popolazione, ecc..) li hai scelti a caso o c'è dietro un tuo studio particolare?
"irelimax":
visto che siamo partiti per inserire il TS nel ciclo principale in modo da farlo rannare ad ogni ciclo subito dopo la mutation,
bhe questa non è una mia scelta, deve essere così, se no non ha molto senso usare la ricerca locale...
esso dovrebbe copiare la popolazione P nella population e passarla al GA per fare nuovamente tutte le operazioni descritte da te passo passo.
ok, e questo conferma ciò che ho pensato, la tabu search descritta in quel testo non va bene. Poi abbiamo interpretato male (ho intrpretato) il testo. Capita spesso se al descrizione è fatta in poche righe.
Ho in mente altro per risolvere, quello che cambia è quando dice "after finding tabu" si modifica la popolazione corrente con gli elementi della aspiration list, quest'ultimi sono creati dalla Tabu_search con un qualche metodologia che guardo ora e non si basano sempre sulla popolazione.
Se dovessimo utilizzare la popolazione P come base per trovare una soluzione con miglio fitness (o distanza) non troveremmo nulla di migliore, perchè in posizione P[0] c'è giò la quota massima possibile. E' chiaro cosa non va in questo modello?
Perciò quello che cambia:
- aspiration list saranno salvati nuovi punti trovati con la TS
- la popolazione P è modificato DOPO la TS con il metodo già descritto negli altri post
- la last population corrisponde a P, la popolazione corrente corrsiponde a P modificata con AL
così ha anche più senso
Altre cose, i vari parametri del GA (elite, popolazione, ecc..) li hai scelti a caso o c'è dietro un tuo studio particolare?
capito in parte. infatti Fp e P sembravano ridondanti. ma non capisco perchè vuoi modificare la procedura che inserisce gli elementi nell'aspiration list. abbiamo detto che quando scade il tabu time per un qualche elemento lo inseriamo nell'aspiration list tramite le istruzioni
é questo che vuoi modificare? se si perchè?
I vari paramentri che ho impostato nel GA sono stati frutto di consigli altrui ottenuti come se avessi implementato soltanto il GA (cioè senza il TS)
if(time_zero(TL)){
add_al(delete_tl(TL),AL);
é questo che vuoi modificare? se si perchè?
I vari paramentri che ho impostato nel GA sono stati frutto di consigli altrui ottenuti come se avessi implementato soltanto il GA (cioè senza il TS)
Allora il problema (lasciando stare FP che ti dissi era na pezza per farti funzionare il codice  ) della nostra interpretazione è che i dati oltre ad essere ridontanti, se DISTANCE() valuta gli elementi in P[] e TL, vuol dire valutare gli STESSI elementi, cioè in P=TL in momenti diversi. Che miglioramenti ci sono? nessuno al massimo si può parlare di permutazione degli elementi di P e nient'altro.
) della nostra interpretazione è che i dati oltre ad essere ridontanti, se DISTANCE() valuta gli elementi in P[] e TL, vuol dire valutare gli STESSI elementi, cioè in P=TL in momenti diversi. Che miglioramenti ci sono? nessuno al massimo si può parlare di permutazione degli elementi di P e nient'altro.
il dominio di TS è P la popolazione il codominio è sempre P ma permutato, se lo riordiniamo avremo li stessi elementi di P, cioè non ci sono miglioramenti, mi segui?
Se vuoi metterla così:
- i dati in TL sono presi da P
- i dati in AL sono presi da TL (in iterazioni diverse)
perciò i dati in AL sono quelli di P, mi chiedo dove sta il miglioramente se all'uscita modificando P con AL, riordini i dati per l'elite, la fitness migliore è la stessa di P prima della TS..
in poche parole la Tabu_search non è una funzione a parte che cerca soluzioni su P, ma cerca soluzioni migliori su tutte le generazioni ed è una parte integrante dell'algoritmo GA. Ok ci sono e ti scrivo il codice
il dominio di TS è P la popolazione il codominio è sempre P ma permutato, se lo riordiniamo avremo li stessi elementi di P, cioè non ci sono miglioramenti, mi segui?
Se vuoi metterla così:
- i dati in TL sono presi da P
- i dati in AL sono presi da TL (in iterazioni diverse)
perciò i dati in AL sono quelli di P, mi chiedo dove sta il miglioramente se all'uscita modificando P con AL, riordini i dati per l'elite, la fitness migliore è la stessa di P prima della TS..
in poche parole la Tabu_search non è una funzione a parte che cerca soluzioni su P, ma cerca soluzioni migliori su tutte le generazioni ed è una parte integrante dell'algoritmo GA. Ok ci sono e ti scrivo il codice
si ok certo che stupida! ovviamente il TS che abbiamo implementato finora non fa altro che rimescolare le carte come hai detto anche tu ritrovando alla fine la stessa popolazione generate dal GA. questo succede perchè nella TS non abbiamo implementato una funzione che genera nuovi valori (ricordi la generazione del vicinato di cui parlavamo tempo fa?). Mi chiedevo se, per far ciò, potessimo usare la stessa funzione implementata per generare numeri casuali nel GA. che ne pensi? Mi accorgo però che da questa domanda ne nascono tante altre ad esempio:
Il TS riceve la popolazione dal GA. Di quale individuo generiamo il vicinato? da uno o da più trai i migliori?
Il TS riceve la popolazione dal GA. Di quale individuo generiamo il vicinato? da uno o da più trai i migliori?
si ok certo che stupida! ovviamente il TS che abbiamo implementato finora non fa altro che rimescolare le carte come hai detto anche tu ritrovando alla fine la stessa popolazione generate dal GA. questo succede perchè nella TS non abbiamo implementato una funzione che genera nuovi valori (ricordi la generazione del vicinato di cui parlavamo tempo fa?).
esatto esatto
non si hanno nuovi "vicini" si gira la stessa minestra
Mi chiedevo se, per far ciò, potessimo usare la stessa funzione implementata per generare numeri casuali nel GA. che ne pensi?
questa sarebbe la soluzione in una normale ricerca locale e ad una definizione di vicinato nel continuo (io di solito lavoro nel discreto), e si valutano nuove soluzioni migliori, ma se leggi sotto la traccia è interpretabile in un altro modo.
Questa soluzione che hai detto la teniamo da parte in caso di necessità
Allora invece di implemetare una fun TS, incorporiamo direttamente la funzione che abbiamo scritto dopo la mutazione:
mutation(population); //mutate
insertion_fit_sort(population);
add_tl(&(population[0]),TL,TABU_TIME);
if(time_zero(TL)){
add_al(delete_tl(TL),AL);
}
k=0;
while(k<DIM_POP){
f=TL->head;
while(f!=TL->tail){
if(DISTANCE(&(population[k]),&(TL->tabu_l[f].ch))){ //se la distanza è minore di R inserisci elemento in AL
if(emptyp_al(AL)){ //se la AL è vuota
cp_chrom(&(population[it_FP]),&(population[k]));
it_FP--;
/* sostituire il cromosoma ella popolazione attuale con quello di fitness minore degli antenati */
/* (per ogni iterazione si decresce di indice)*/
}
else{
cp_chrom(delete_al(AL),&(population[k]));
}
}
f=next_tl(f,TL);
}
k++;
}
it_FP = DIM_POP-1;
time_zero_TT(TL);ora le parti di inizializzazione delle variabili usate saranno all'esterno del ciclo di iterazione del GA:
TABU_TIME = ((int)ceil(num/50))*36; //is the smallest integer not less than (DIM_POP-2)/50
DIM_TL = (int)ceil(num/2);
tabu_list* TL = init_tl(DIM_TL); //declaration and initialization of TL
if(TL==NULL){
exit(0);
}
//la dimensione conta poco della AL, non la si riempirà mai, perchè è limitata dal TABU_TIME=0
aspiration_list* AL = init_al(DIM_TL);
if(AL==NULL){
exit(0);
}e prima dell'inputa da tastiera dichiari le variabili utili al codice scritto da me:
int TABU_TIME; //is the smallest integer not less than (DIM_POP-2)/50 int DIM_TL; int f=0; int k = 0; int it_FP = DIM_POP-1;
Ora ci sono alcune cose da sistemare o rivedere;
- decidere cosa fare a P[0] quando lo si assegna Tabu, penso che una soluzione sia sostituire P[0] con il calore di fitness minore P[DIM_POP]
- decidere cosa fare con DISTANCE=0 cioè quando un cromosoma (punti) sono uguali nella stessa popolazione con gli elementi Tabu (dovuti o alla non sostituzione di P[0] o se P==P[0]), possibile soluzione uguale di sopra oppure possibile aspiration criteria
- è possibile implementare l'aspiration criteria (solo dopo aver sistemato tutto il resto)
- sistemare TABU_TIME, possibile implementarlo invece che fisso in modo reactive o random (penso random), e DIM_LIST_TL devo rivederlo perchè può variare con l'iterazione decisa a tastiera
l'algoritmo comunque è questo non ci sono altre interpretazioni
ok, così dovrebbe andare, condizioni aggiunte (da quelle in elenco nell'altro post):
- sostituito il best fitness diventato Tabu, con il worst fitness
- modificata la condizione di DISTANCE, praticamente è tornata all'originale questo perchè ad ogni iterazione modificando la popolazione attuale con gli elementi in AL, si cerca di distanziare i punti così da evitare plateau o massimi locali, se non si lascia anche quando la distanza è 0 cioè è lo stesso cromosoma, questo punto verrà eliminato e non salavato nella selezione elite.
Ora si può vedere i parametri di tabu_time, io lo terrei fisso...
poi secondo me si può migliorare la ricerca locale, ma è qualcosa di secondario.
Io ho fatto qualche test sembra buono
- sostituito il best fitness diventato Tabu, con il worst fitness
add_tl(&(population[0]),TL,TABU_TIME);
cp_chrom(&(population[it_FP]),&(population[0]));
it_FP--;
if(time_zero(TL)){
add_al(delete_tl(TL),AL);
}
k=0;
while(k<DIM_POP){
f=TL->head;
while(f!=TL->tail){
if(DISTANCE(&(population[k]),&(TL->tabu_l[f].ch))){ //se la distanza è minore di R inserisci elemento in AL
if(emptyp_al(AL)){ //se la AL è vuota
cp_chrom(&(population[it_FP]),&(population[k]));
it_FP--;
/* sostituire il cromosoma ella popolazione attuale con quello di fitness minore degli antenati */
/* (per ogni iterazione si decresce di indice)*/
}
else{
cp_chrom(delete_al(AL),&(population[k]));
}
}
f=next_tl(f,TL);
}
k++;
}
time_zero_TT(TL);
it_FP = DIM_POP-1;- modificata la condizione di DISTANCE, praticamente è tornata all'originale questo perchè ad ogni iterazione modificando la popolazione attuale con gli elementi in AL, si cerca di distanziare i punti così da evitare plateau o massimi locali, se non si lascia anche quando la distanza è 0 cioè è lo stesso cromosoma, questo punto verrà eliminato e non salavato nella selezione elite.
boolean DISTANCE(chrom* b,chrom* d){
return (boolean)(sqrt(pow(b->point[0]-d->point[0],2.0)+pow(b->point[1]-d->point[1],2.0))<R);
}Ora si può vedere i parametri di tabu_time, io lo terrei fisso...
poi secondo me si può migliorare la ricerca locale, ma è qualcosa di secondario.
Io ho fatto qualche test sembra buono
scusa facciamo un passo indietro e guardiamo la funzione add_tl che ti ho riscritto qui sotto:
quando si verifica per la prima volta che la tabu list è piena, richiamiamo la funzione delete_tl che mi dovrebbe eliminare come tu stesso dice l'elemento più vecchio della tabu list. a questo punto tl->tail= DIM_LIST-1 condizione che ci ha fatto eseguire la funzione delete. ma una volta usciti dalla delete eseguiamo le altre 3 operazioni successive che puoi ben vedere dal codice. tale sequenza di istruzioni copiano il nuovo valore tabu (n) nell'ultima posizione della tabu list perchè tl->tail è ancora DIM_LIST -1. non dovrebbe essere copiato nella prima posizione della tanu list cioè in ta_l[0]?
riguardo le tue osservazioni precedentemente fatte siamo apposto.
void add_tl(chrom* n,tabu_list* tl,int TABU_TIME){
//se la tabu_list è piena si elimina l'elemento più vecchio e distante dal cromosoma migliore
if (fullp(tl)){
delete_tl(tl);
}
tl->tabu_l[tl->tail].ch.point[0]=n->point[0];
tl->tabu_l[tl->tail].ch.point[1]=n->point[1];
tl->tabu_l[tl->tail].ch.fit = n->fit;
tl->tabu_l[tl->tail].tabu_time = TABU_TIME;
tl->tail = next_tl(tl->tail,tl);
}
quando si verifica per la prima volta che la tabu list è piena, richiamiamo la funzione delete_tl che mi dovrebbe eliminare come tu stesso dice l'elemento più vecchio della tabu list. a questo punto tl->tail= DIM_LIST-1 condizione che ci ha fatto eseguire la funzione delete. ma una volta usciti dalla delete eseguiamo le altre 3 operazioni successive che puoi ben vedere dal codice. tale sequenza di istruzioni copiano il nuovo valore tabu (n) nell'ultima posizione della tabu list perchè tl->tail è ancora DIM_LIST -1. non dovrebbe essere copiato nella prima posizione della tanu list cioè in ta_l[0]?
riguardo le tue osservazioni precedentemente fatte siamo apposto.
Ciao,
ma questo commento lo ho scritto io?
esatto
non direi.
Può succedere che tail corrisponda alla posizone DIM_LIST, ma prova a vedere come è scritta la funzione fullp()...
non t[0] ma la prima posizione libera, cioè corrispondente a next(), stessa cosa prova a vedere la definizione della funzione..
Non è un vettore lineare, è un vettore circolare (in letteratura ha vari normi) con proprietà FIFO.
spero anchio che siamo apposto
//se la tabu_list è piena si elimina l'elemento più vecchio e distante dal cromosoma migliore
ma questo commento lo ho scritto io?
quando si verifica per la prima volta che la tabu list è piena, richiamiamo la funzione delete_tl che mi dovrebbe eliminare come tu stesso dice l'elemento più vecchio della tabu list.
esatto
a questo punto tl->tail= DIM_LIST-1 condizione che ci ha fatto eseguire la funzione delete.
non direi.
Può succedere che tail corrisponda alla posizone DIM_LIST, ma prova a vedere come è scritta la funzione fullp()...
tale sequenza di istruzioni copiano il nuovo valore tabu (n) nell'ultima posizione della tabu list perchè tl->tail è ancora DIM_LIST -1. non dovrebbe essere copiato nella prima posizione della tanu list cioè in ta_l[0]?
non t[0] ma la prima posizione libera, cioè corrispondente a next(), stessa cosa prova a vedere la definizione della funzione..
Non è un vettore lineare, è un vettore circolare (in letteratura ha vari normi) con proprietà FIFO.
riguardo le tue osservazioni precedentemente fatte siamo apposto.
spero anchio che siamo apposto
ok c'ho pensato ancora un pò e adesso quadra
"irelimax":
scusa ma non riesco proprio a capire.
potresti fare un esempio numerico partendo dalla condizione di tabu list piena, in modo da entrare nella funzione delete?
Un'immagine è più esauriente di mille parole:
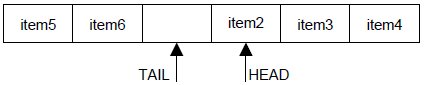
questa è una coda piena, è lo stato prima della chiama ad addl(), cioè:
[5,6,_,2,3,4] tail=2 head=3
Quando chiami addl() c'è il controllo se è piena perciò chiama fullp(), e controlla se next(tail)==head,
cioè se la freccia tail spostato di una posizione è uguale ad head, cioè c'è possibilità di sovrascrittura.
In questo caso, nel nostro codice (la tabu_search lo permette di solito non così e si dovrebbe riporatare errore) eliminiamo un elemento in testam cioè spostiamo di una posizione a destra head, perciò:
[5,6,_,_,3,4] tail=2 head=4
aggiungiamo un elemento in coda facciamo 1 e diviene:
[5,6,1,_,3,4] tail=3 head=4
più chiaro così?
se vuoi altre immagini vedi qua
ci sono da aggiungere alcuni controlli al delete, li facciamo alla fine non sono importanti...
volevo un po' finire la faccenda, il tabu_time ho valutato un po' come sistemarlo, penso che debba essere collegato con l'elite rate questo perchè i fitness migliori sono mantenuti per 5 (se ricordo bene) iterazioni, e questo penso sia una buona definizione.
noi lo calcoliamo come una distanza di hamming senza sovrapposizione di fitness (o generazioni uguali) in calcoli:
- TABU_TIME = (2*ELITIST)+1
la lunghezza della TL non sono ancora convinto, ma si può provare con:
- DIM_TL = 2*TABU_TIME
io ho aggiunto anche un aspiration_criteria ma non è qualcosa di molto standard ho valutato se i dati son migliori, direi di sì, ma come puoi supporre i test che ho fatto sono inutili, cioè i valori che ho trovato posson cambiare da pc a pc
ora le cose da fare son davvero poche, devi sistemarti un po' il codice, modularizzarlo perchè come è messo è parecchio incasinato.
Perciò l'algoritmo è finito
(a parte valutare se cambiare il tabu_time o la dim_tl, ma al massimo cambiano per una costante).
noi lo calcoliamo come una distanza di hamming senza sovrapposizione di fitness (o generazioni uguali) in calcoli:
- TABU_TIME = (2*ELITIST)+1
la lunghezza della TL non sono ancora convinto, ma si può provare con:
- DIM_TL = 2*TABU_TIME
io ho aggiunto anche un aspiration_criteria ma non è qualcosa di molto standard ho valutato se i dati son migliori, direi di sì, ma come puoi supporre i test che ho fatto sono inutili, cioè i valori che ho trovato posson cambiare da pc a pc
ora le cose da fare son davvero poche, devi sistemarti un po' il codice, modularizzarlo perchè come è messo è parecchio incasinato.
Perciò l'algoritmo è finito
(a parte valutare se cambiare il tabu_time o la dim_tl, ma al massimo cambiano per una costante).
L'aspiration criteria lo ho così definito:
scegliere un valore random modulato al numero di iterazioni, ad ogni iterazione si diminusisce questo valore, quando diverrà 0 si guarda il valore di fitness massimo attuale e si confronta con quello salvato in precedenza, se è migliore si sostituisce l'attuale con quello precedente così da far ritornare la ricerca sui passi corretti per cercare la miglior soluzione.
Dal mio punto di vista si può migliorare questa definizione, ma al momento ho cercato quella più semplice per questo tipo di problema essendo un ibrido.
Possibili miglioramenti alla ricerca locale possono essere questi:
(1)Allo stato attuale quando finiscono le iterazioni rimangono dei punti con buoni fitness nella AL e TL, questo comporta una perdita di informazione, adesso si può cercare il massimo di queste due liste e confrontarlo con il massimo dell'algoritmo.
(2)Di solito si modella l'algoritmo in modo che ad un certo punto non si accettano più soluzioni migliori prima della fine delle iterazioni specificate così da svuotare man mano la TL, cioè a num-TABU_TIME non si accettano più soluzioni nuove.
(3)Un'altra possibilità è fare a cicli stabiliti di ricerca tabu e di ricerca locale normale, cioè fare ciclicamente (2) ad iterazioni di 2*TABU_TIME.
comunque facendo ulteriori prove questi sono i risultati, ad iterazioni di potenze di 2 (come già ti ho scritto):
(1)
con i massimi esplicitati:
(2)
con i massimi esplicitati:
direi che è una buona approssimazione
in (2) ci sono migliori risultati nella ricerca vera, e non utilizzando cose secondarie come l'aspiration criteria. Valutando bene si possono fari miglioramenti evidenti, devi vedere te come vuoi procedere
PS: se non lo hai notato la TL è di dimensione tale da non poter essere mai vermente piena, perchè viene svuotata ad ogni iterazioni. Quel discorso del post precedente è valido solo in caso di utilizzare altri tipi di proibizioni (ho scritto il codice così per tua comodità se vuoi usare tipo proibizione random o reattiva).
scegliere un valore random modulato al numero di iterazioni, ad ogni iterazione si diminusisce questo valore, quando diverrà 0 si guarda il valore di fitness massimo attuale e si confronta con quello salvato in precedenza, se è migliore si sostituisce l'attuale con quello precedente così da far ritornare la ricerca sui passi corretti per cercare la miglior soluzione.
aspiration_criteria = ((int)rand()%num)+1;
AC = aspiration_criteria;
inserire da tastiera num
...
if(j==0){
cp_chrom(&(population[0]),mac);
}
if(AC==0){
if(population[0].fit > mac->fit){
cp_chrom(&(population[0]),mac);
}
else{
cp_chrom(mac,&(population[0]));
}
AC = aspiration_criteria; (un'altra possibilità è utilizzare un valore random%num
}
add TL ...
...
AC--
fine iterazioneDal mio punto di vista si può migliorare questa definizione, ma al momento ho cercato quella più semplice per questo tipo di problema essendo un ibrido.
Possibili miglioramenti alla ricerca locale possono essere questi:
(1)Allo stato attuale quando finiscono le iterazioni rimangono dei punti con buoni fitness nella AL e TL, questo comporta una perdita di informazione, adesso si può cercare il massimo di queste due liste e confrontarlo con il massimo dell'algoritmo.
(2)Di solito si modella l'algoritmo in modo che ad un certo punto non si accettano più soluzioni migliori prima della fine delle iterazioni specificate così da svuotare man mano la TL, cioè a num-TABU_TIME non si accettano più soluzioni nuove.
(3)Un'altra possibilità è fare a cicli stabiliti di ricerca tabu e di ricerca locale normale, cioè fare ciclicamente (2) ad iterazioni di 2*TABU_TIME.
comunque facendo ulteriori prove questi sono i risultati, ad iterazioni di potenze di 2 (come già ti ho scritto):
(1)
con i massimi esplicitati:
(2)
con i massimi esplicitati:
direi che è una buona approssimazione
in (2) ci sono migliori risultati nella ricerca vera, e non utilizzando cose secondarie come l'aspiration criteria. Valutando bene si possono fari miglioramenti evidenti, devi vedere te come vuoi procedere
PS: se non lo hai notato la TL è di dimensione tale da non poter essere mai vermente piena, perchè viene svuotata ad ogni iterazioni. Quel discorso del post precedente è valido solo in caso di utilizzare altri tipi di proibizioni (ho scritto il codice così per tua comodità se vuoi usare tipo proibizione random o reattiva).
Ancora alcune cose che non mi convingono.
1) I fitness migliori non sono mantenuti per 5 iterazioni come tu dici bensi per una soltanto: infatti ai primi 5 non applichiamo crossover e mutation ma al ciclo successivo, a causa dell'ordinamento (con l'insertion sort), questi primi 5 possono variare perchè può capitare che qualche cromosoma che si trovava tra la 6a e la 99a posizione salga fino alle prime 5 in seguito alle operazioni di crossover e mutation. Correggimi se sbaglio.
2) Come avevi intuito tu stesso riguardo all'algoritmo di un pò di tempo fa non ancora ultimato, la tabu search non faceva altro che cambiare le posizioni degli elementi senza apportare nessun miglioramento alla ricerca visto che la popolazione veniva di volta in volta ordinata. Ma penso che tutto ciò succede ancora dato che dopo le operazioni del tabu search riordinola popolazione dando al GA la stessa che lu stesso aveva passato al tabu search. In sostanza il tabu search è fittizio in questo codice. Ti mando un altro messaggio tra un pò con il codice implementato fino ad ora
3) inoltre mi hai fatto notare ad un certo punto del programma che non c'era bisogno di ordinare e che bastava cercare il massimo. Ma questo massimo viene poi memorizzato nella variabile mac? esso non sarà mai in population[0] visto che non abbiamo ordinato? penso che si deve sistemare il seguente:
1) I fitness migliori non sono mantenuti per 5 iterazioni come tu dici bensi per una soltanto: infatti ai primi 5 non applichiamo crossover e mutation ma al ciclo successivo, a causa dell'ordinamento (con l'insertion sort), questi primi 5 possono variare perchè può capitare che qualche cromosoma che si trovava tra la 6a e la 99a posizione salga fino alle prime 5 in seguito alle operazioni di crossover e mutation. Correggimi se sbaglio.
2) Come avevi intuito tu stesso riguardo all'algoritmo di un pò di tempo fa non ancora ultimato, la tabu search non faceva altro che cambiare le posizioni degli elementi senza apportare nessun miglioramento alla ricerca visto che la popolazione veniva di volta in volta ordinata. Ma penso che tutto ciò succede ancora dato che dopo le operazioni del tabu search riordinola popolazione dando al GA la stessa che lu stesso aveva passato al tabu search. In sostanza il tabu search è fittizio in questo codice. Ti mando un altro messaggio tra un pò con il codice implementato fino ad ora
3) inoltre mi hai fatto notare ad un certo punto del programma che non c'era bisogno di ordinare e che bastava cercare il massimo. Ma questo massimo viene poi memorizzato nella variabile mac? esso non sarà mai in population[0] visto che non abbiamo ordinato? penso che si deve sistemare il seguente:
//basta cercare il massimo non serve ordinare.
insertion_fit_sort(population);
if(j==0){
cp_chrom(&(population[0]),max);
}
if(AC==0){.......
Ciao,
mi fa piacere, vedere, che non ti sei arresa
Sì certo tutto corretto
quello che ho proposto io è una cosa un po' da interpretare. Quello che voglio evitare è far combinare figli di questa elite tra loro. Nel senso che il primo cromosoma dell'elite non si combinerà fino a distanza TL cosa che per definizione di "distanza di hamming", ma questo come hai detto può non avvenire. Il Tabu_time basterebbe anche solo ELITIST+1 per rimanere legati all'algoritmo genetico ed alla definizioni di cromosoma. si può anche scegliere a caso un valore, ma devi basarti su qualche fatto che "può avvenire"
questo prima della modifica di pag. 3
no questo non avviene più, ti basta vedere cosa accade alla AL (fai una print all'interno delle condizioni di DISTANCE) ad ogni iterazione della TS.
ok
Non servirebbe ai fini dell'algoritmo, ma è utile per due ragioni:
- hai il best in posizioni P[0]
- hai tutti i small fitness ordinate e puoi trovarli con un intero it_FP e diminuirlo.
Se non fosse ordinato dovresti cercare il small tutte le volte. Ho scritto quel commento prima di notare la sua utilità
Invece l'ordinamento alla fine è inutile, cioè alla chiusura dell'iterazione e cerchi il massimo per stamparlo, lì basta cercarlo e salvarsi la posizione. O se non vuoi scrivere altro codice basta ordinarlo anche, tanto lo fai UNA volta
mi fa piacere, vedere, che non ti sei arresa
"irelimax":
1) I fitness migliori non sono mantenuti per 5 iterazioni come tu dici bensi per una soltanto: infatti ai primi 5 non applichiamo crossover e mutation ma al ciclo successivo, a causa dell'ordinamento (con l'insertion sort), questi primi 5 possono variare perchè può capitare che qualche cromosoma che si trovava tra la 6a e la 99a posizione salga fino alle prime 5 in seguito alle operazioni di crossover e mutation. Correggimi se sbaglio.
Sì certo tutto corretto
quello che ho proposto io è una cosa un po' da interpretare. Quello che voglio evitare è far combinare figli di questa elite tra loro. Nel senso che il primo cromosoma dell'elite non si combinerà fino a distanza TL cosa che per definizione di "distanza di hamming", ma questo come hai detto può non avvenire. Il Tabu_time basterebbe anche solo ELITIST+1 per rimanere legati all'algoritmo genetico ed alla definizioni di cromosoma. si può anche scegliere a caso un valore, ma devi basarti su qualche fatto che "può avvenire"
2) Come avevi intuito tu stesso riguardo all'algoritmo di un pò di tempo fa non ancora ultimato, la tabu search non faceva altro che cambiare le posizioni degli elementi senza apportare nessun miglioramento alla ricerca visto che la popolazione veniva di volta in volta ordinata.
questo prima della modifica di pag. 3
Ma penso che tutto ciò succede ancora dato che dopo le operazioni del tabu search riordinola popolazione dando al GA la stessa che lu stesso aveva passato al tabu search. In sostanza il tabu search è fittizio in questo codice.
no questo non avviene più, ti basta vedere cosa accade alla AL (fai una print all'interno delle condizioni di DISTANCE) ad ogni iterazione della TS.
Ti mando un altro messaggio tra un pò con il codice implementato fino ad ora
ok
3) inoltre mi hai fatto notare ad un certo punto del programma che non c'era bisogno di ordinare e che bastava cercare il massimo.
Non servirebbe ai fini dell'algoritmo, ma è utile per due ragioni:
- hai il best in posizioni P[0]
- hai tutti i small fitness ordinate e puoi trovarli con un intero it_FP e diminuirlo.
Se non fosse ordinato dovresti cercare il small tutte le volte. Ho scritto quel commento prima di notare la sua utilità
Invece l'ordinamento alla fine è inutile, cioè alla chiusura dell'iterazione e cerchi il massimo per stamparlo, lì basta cercarlo e salvarsi la posizione. O se non vuoi scrivere altro codice basta ordinarlo anche, tanto lo fai UNA volta

 Accedi a tutti gli appunti
Accedi a tutti gli appunti
 Tutor AI: studia meglio e in meno tempo
Tutor AI: studia meglio e in meno tempo