Programmazione dinamicati

Ciao a tutti vorrei chiedervi un aiuto riguardo la ricerca del più lunga sottosequenza comune..
Ho l'algoritmo per creare la matrice ,cioè quello che parte da sinistra fino in basso a destra,ma non quello per trovare la sottosequenza ,cioè che analizza la matrice da in basso a destra a a in alto a sinistra..
Qualcuno di voi può spiegarmi come funzione quell'algoritmo??
Posto una matrice già realizzata...

il risultato che nn riesco ad ottenere é CBBA
grazie !!!
Ho l'algoritmo per creare la matrice ,cioè quello che parte da sinistra fino in basso a destra,ma non quello per trovare la sottosequenza ,cioè che analizza la matrice da in basso a destra a a in alto a sinistra..
Qualcuno di voi può spiegarmi come funzione quell'algoritmo??
Posto una matrice già realizzata...
il risultato che nn riesco ad ottenere é CBBA
grazie !!!
Risposte

"Gianni91":
Ho l'algoritmo per creare la matrice ,cioè quello che parte da sinistra fino in basso a destra,ma non quello per trovare la sottosequenza ,cioè che analizza la matrice da in basso a destra a a in alto a sinistra..
In che senso "non hai l'algoritmo", dove la hai trovato, su un qualsiasi libro di algoritmica è riportato...
Poi cosa non comprendi, come funziona il problema LCS o la tecnica utilizzata dall'algoritmo cioè di programmazione dinamica?
Non so come trovare la soluzione ottimale,dopo aver ottenuto quella tabella, realizzata tramite un algoritmo (algoritmo di programmazione dinamica)trovato sulla mia dispensa...
nessuno può aiutarmi???... 
problema risolto... 
@Gianni91:
chiedo scusa di non averti più risposto sull'argomento.
Me ne sono completamente scordato...troppe cose da pensare in questo periodo.
Se hai risolto ok, se no son qua.
Se hai domande, ti rispondo volentieri
chiedo scusa di non averti più risposto sull'argomento.
Me ne sono completamente scordato...troppe cose da pensare in questo periodo.
Se hai risolto ok, se no son qua.
Se hai domande, ti rispondo volentieri
Ciao innanzitutto,volevo dirti che non c'è bisogno di scusarti,visto che nessuno è obbligato a rispondere.. 
Cmq vorrei approfittare ,per chiederti di chiarirmi un paio di dubbi..
Per ora scrivo il primo,poi se sei disponibile, scrivo anche l'altro..
Questa é la traccia del mio problema..
Sia dato un albero binario t ad etichette intere. Si scriva una funzione duplica che restituisce un
puntatore ad un altro albero binario identico a t, ma con le etichette raddoppiate.
la cosa che non mi é chiara, é come si comporta la ricorsione??
prima va tutta a destra e poi tutta a sinistra(tanto per intenderci) ,ma in questo caso come fa a raddoppiare i nodi di destra.Altrimenti se esegue solo una volta entrambi
arriva subito al return e non fa quello che deve fare..
Spero sia chiaro il mio problema ,anche se spiegato alla meglio
Cmq vorrei approfittare ,per chiederti di chiarirmi un paio di dubbi..
Per ora scrivo il primo,poi se sei disponibile, scrivo anche l'altro..
Questa é la traccia del mio problema..
Sia dato un albero binario t ad etichette intere. Si scriva una funzione duplica che restituisce un
puntatore ad un altro albero binario identico a t, ma con le etichette raddoppiate.
Node* duplica(Node *t) {
if (!t) return NULL;
Node *np = new Node();
np->label = 2* t->label;
np->left = duplica(t->left);
np->right = duplica(t->right);
return np;
la cosa che non mi é chiara, é come si comporta la ricorsione??
prima va tutta a destra e poi tutta a sinistra(tanto per intenderci) ,ma in questo caso come fa a raddoppiare i nodi di destra.Altrimenti se esegue solo una volta entrambi
np->left = duplica(t->left); np->right = duplica(t->right);
arriva subito al return e non fa quello che deve fare..
Spero sia chiaro il mio problema ,anche se spiegato alla meglio
Ciao,
sì certo, ma visto che avevo intenzione di darti una qualche risposta, mi sembrava doveroso dirti il motivo della non-risposta
aspetta un attimo, il codice è in allegato al problema o lo hai scritto te?
se è allegato, allora non capisco perchè parli di "raddoppio dei nodi". Da come lo ho interpretato io si parla di "raddoppio delle etichette", cosa che il codice fa.
Praticamente tu ricrei l'albero con le etichette moltiplicate per $2$. Si poteva interpretare anche come "raddoppio delle etichette per nodo" cioè due "etichette" con lo stesso valore intero.
No, sbagli. Questa che fai è una visita in pre-ordine.
Va in visita nei rami left (sinistra) dell'albero originale, quando raggiunge una foglia (identificata con NULL) ritorna, e visita i rami right (destra).
Poi come scritto sopra, non raddoppia i nodi, ma solo il valore intero dell'etichetta, ricreando la struttura dati dell'albero binario.
mmm non capisco questo. Questo può succedere solo se hai un albero (che passi alla funzione duplica()) composto solo da un nodo (la radice) e i figli sono due foglie (NULL).
O forse non sai come funzione una chiamata ricorsiva? cioè come si riesce a far corrispondere una chiamata e far "ripartire" dallo stesso punto il codice chiamante...
Se hai dubbi chiedi pure
"Gianni91":
volevo dirti che non c'è bisogno di scusarti,visto che nessuno è obbligato a rispondere..
sì certo, ma visto che avevo intenzione di darti una qualche risposta, mi sembrava doveroso dirti il motivo della non-risposta
Sia dato un albero binario t ad etichette intere. Si scriva una funzione duplica che restituisce un
puntatore ad un altro albero binario identico a t, ma con le etichette raddoppiate.
Node* duplica(Node *t) { if (!t) return NULL; Node *np = new Node(); np->label = 2* t->label; np->left = duplica(t->left); np->right = duplica(t->right); return np;
aspetta un attimo, il codice è in allegato al problema o lo hai scritto te?
se è allegato, allora non capisco perchè parli di "raddoppio dei nodi". Da come lo ho interpretato io si parla di "raddoppio delle etichette", cosa che il codice fa.
Praticamente tu ricrei l'albero con le etichette moltiplicate per $2$. Si poteva interpretare anche come "raddoppio delle etichette per nodo" cioè due "etichette" con lo stesso valore intero.
la cosa che non mi é chiara, é come si comporta la ricorsione??
prima va tutta a destra e poi tutta a sinistra(tanto per intenderci) ,ma in questo caso come fa a raddoppiare i nodi di destra.
No, sbagli. Questa che fai è una visita in pre-ordine.
Va in visita nei rami left (sinistra) dell'albero originale, quando raggiunge una foglia (identificata con NULL) ritorna, e visita i rami right (destra).
Poi come scritto sopra, non raddoppia i nodi, ma solo il valore intero dell'etichetta, ricreando la struttura dati dell'albero binario.
Altrimenti se esegue solo una volta entrambi
np->left = duplica(t->left); np->right = duplica(t->right);
arriva subito al return e non fa quello che deve fare..
mmm non capisco questo. Questo può succedere solo se hai un albero (che passi alla funzione duplica()) composto solo da un nodo (la radice) e i figli sono due foglie (NULL).
O forse non sai come funzione una chiamata ricorsiva? cioè come si riesce a far corrispondere una chiamata e far "ripartire" dallo stesso punto il codice chiamante...
Se hai dubbi chiedi pure
"ham_burst":
Sia dato un albero binario t ad etichette intere. Si scriva una funzione duplica che restituisce un
puntatore ad un altro albero binario identico a t, ma con le etichette raddoppiate.
Node* duplica(Node *t) { if (!t) return NULL; Node *np = new Node(); np->label = 2* t->label; np->left = duplica(t->left); np->right = duplica(t->right); return np;
aspetta un attimo, il codice è in allegato al problema o lo hai scritto te?
se è allegato, allora non capisco perchè parli di "raddoppio dei nodi". Da come lo ho interpretato io si parla di "raddoppio delle etichette", cosa che il codice fa.
Praticamente tu ricrei l'albero con le etichette moltiplicate per $2$. Si poteva interpretare anche come "raddoppio delle etichette per nodo" cioè due "etichette" con lo stesso valore intero.
Il codice nn é scritto da me ,ma é preso da un esercizio svolto.Si ho sbagliato a scrivere intendevo duplica le etichette dei nodi..
Adesso veniamo,alla ricorsione.
Ti spiego secondo me come funziona la ricorsione..
Quando chiama il duplica(t->left),richiama la funzione stessa, rivaluta la prime condizioni
if (!t) return NULL; Node *np = new Node(); np->label = 2* t->label;
poi richiama dinuovo duplica(t->left), e rifa questo discorso fino a quando non é NULL e poi procede con le chiamate a duplica(t->rght)...spero sia cosi
La cosa che davvero non riesco a capire,che se la funzione analizza il sottoalbero sinistro,come fa a raddoppiara le etichette dei nodi presenti a destra del sottoalbero sinisto???
ciao
"Gianni91":
Quando chiama il duplica(t->left),richiama la funzione stessa, rivaluta la prime condizioni
if (!t) return NULL; Node *np = new Node(); np->label = 2* t->label;
poi richiama dinuovo duplica(t->left), e rifa questo discorso fino a quando non é NULL e poi procede con le chiamate a duplica(t->rght)...spero sia cosi
esatto
La cosa che davvero non riesco a capire,che se la funzione analizza il sottoalbero sinistro,come fa a raddoppiara le etichette dei nodi presenti a destra del sottoalbero sinisto???
mi sa che ti sei già risposto da solo:
Quando chiama il duplica(t->left),richiama la funzione stessa, rivaluta la prime condizioni
if (!t) return NULL; Node *np = new Node(); np->label = 2* t->label;
poi richiama dinuovo duplica(t->left), e rifa questo discorso fino a quando non é NULL e poi procede con le chiamate a duplica(t->rght)
Credo comunque di non aver compreso a pieno l'algoritmo..
come raggiunge i due punti interrogativi andando sempre a destra o a sinistra a secondo delle rispettive chiamate??
Posto uno schizzo forse può essere di aiuto..

grazie...
come raggiunge i due punti interrogativi andando sempre a destra o a sinistra a secondo delle rispettive chiamate??
Posto uno schizzo forse può essere di aiuto..
grazie...
come scrissi l'algoritmo duplica() utilizza la struttura di visita detta pre-order.
Perciò un'animazione di ciò è più utile di qualsiasi spiegazione:
http://www.primofurno.it/bst/preorder.php
premi "Play >"
ti mostra anche lo stack di visita.
Se hai ancora dubbi chiedi pure
Perciò un'animazione di ciò è più utile di qualsiasi spiegazione:
http://www.primofurno.it/bst/preorder.php
premi "Play >"
ti mostra anche lo stack di visita.
Se hai ancora dubbi chiedi pure
Quindi l'ordine nel mio esempio sarebbe..
10-10-8-5-5-10-2?
10-10-8-5-5-10-2?
"Gianni91":
Quindi l'ordine nel mio esempio sarebbe..
10-10-8-5-5-10-2?
eh no!
10 (radice) - 10 - 8 - 10 - 5 - 2 - 5
forse è meglio che te lo scrivi con nodi distinti (albero binario non di ricerca), tipo
$\ \ \ \ \ \ 1$
$\ \ \ \ 2\ \ \ \ 3$
$\ 4\ \ \ 5\ \ 6\ \ 7$
visita: 1-2-4-5-3-6-7
"ham_burst":
[quote="Gianni91"]Quindi l'ordine nel mio esempio sarebbe..
10-10-8-5-5-10-2?
eh no!
10 (radice) - 10 - 8 - 10 - 5 - 2 - 5
forse è meglio che te lo scrivi con nodi distinti (albero binario non di ricerca), tipo
$\ \ \ \ \ \ 1$
$\ \ \ \ 2\ \ \ \ 3$
$\ 4\ \ \ 5\ \ 6\ \ 7$
visita: 1-2-4-5-3-6-7[/quote]
ok,scusami se sembro ottuso ,ma non riesco a vedere nell'algoritmo quello che fa qui,quando arriva a NUll per il 4(1-2-4),che cosa succede??
Il duplica(t->right) non parte dalla parte di destra della radice,facendo tutto il sottoalbero destro??(3-7)??
Ho pensato che la ricorsione chiamava prima t->left per la parte sinistra e poi t->right per la parte destra(partendo dalla radice chiaramente essendo Pre-Order)..
"Gianni91":
ok,scusami se sembro ottuso ,ma non riesco a vedere nell'algoritmo quello che fa qui,quando arriva a NUll per il 4(1-2-4),che cosa succede??
Il duplica(t->right) non parte dalla parte di destra della radice,facendo tutto il sottoalbero destro??(3-7)??
Ho pensato che la ricorsione chiamava prima t->left per la parte sinistra e poi t->right per la parte destra(partendo dalla radice chiaramente essendo Pre-Order)..
nessun problema!
come pensavo non sai come viene gestita una funzione ricorsiva (hai fatto sistemi operativi?)
Il tuo problema è qualcosa di più profondo che l'algoritmo in se...
Prendiamo come esempio l'albero che ti ho scritto, e minimizziamo le cose utili dell'algoritmo senza troppi formalismi, facendolo divenire solo visita pre-order, perciò:
Node duplica(Node t){
t=NULL := return NULL
t.label <- 2*t.label
t.left <- duplica(t.left)
t.right <- duplica(t.right)
return t;
}ti srotolo le chiamate, prendile come una sequenza legate all'albero sopra, le _____________ sono i confini temporanei del mondo della chiamata (scoping).
chiami duplica(1) con $t$ il nodo radice.
_______________________________________
1.label <-2*1
1.left <- duplica(1.left) qua è la chiamata al nodo con etichetta $2$
_____________________________________
2.label = 2*2
2.left <- duplica(2.left) qua è la chiamata al nodo con etichetta $4$
_________________________________
4.label <- 2*4
(*) 4.left <- duplica(4.left) qua è la chiamata al nodo con etichetta $NULL$, una foglia (da notare sotto i nodi 4-5-6-7 ci sono altri 8 nodi che sono le foglie tutte inizializate a NULL)
__________________________________________
foglia4-1=NULL : return NULL
_____________________________
qua è un ritorno, non essendoci una nuova ricorsione si torna indietro a (*)
4.left <- NULL
4.right <- duplica(4.right)
(**)
4.right <- NULL
return 4 (***)
___________________________
qua è un ritorno, non essendoci una nuova ricorsione si torna indietro a (**) e salvi il valore
foglia4-2=NULL : return NULL
__________________________________
qua stesso ragionamento una volta trovato un "return" salvi il valore.
2.left <- 4 (***)
2.right <- duplica(2.right)
_____________________
qua si rinizia...
5.label <- 2*5
5.left <- duplica(5.left)
....
vedi se ti è più chiaro
"ham_burst":
Node duplica(Node t){ t=NULL := return NULL t.label <- 2*t.label t.left <- duplica(t.left) t.right <- duplica(t.right) return t; }
foglia4-1=NULL : return NULL
_____________________________
qua è un ritorno, non essendoci una nuova ricorsione si torna indietro a (*)
4.left <- NULL
4.right <- duplica(4.right)
(**)
4.right <- NULL
return 4 (***)
___________________________
qua è un ritorno, non essendoci una nuova ricorsione si torna indietro a (**) e salvi il valore
foglia4-2=NULL : return NULL
__________________________________
qua stesso ragionamento una volta trovato un "return" salvi il valore.
2.left <- 4 (***)
2.right <- duplica(2.right)
_____________________
In pratica una volta NULL punta di nuovo al nodo 4,controlla se c'è un nodo a destra,non essendoci niente ritorna 4??
Scusami ma con le liste questa cosa del ritornare indietro nn mi risulta,usavo un puntatore ausiliario..
Adesso viene il punto,se sto puntando a 4 come arrivo a 5,con che comando??
"ham_burst":
qua si rinizia...
5.label <- 2*5
5.left <- duplica(5.left)
....
vedi se ti è più chiaro
Ora una volta che ha finito,con cinque,come fa a puntare alla radice??(probabilmente é lo stesso problema scritto prima)

ps:Non ho fatto sistemi operativi..
ok sono riuscito a complicarti la vita.
Io non ho mai parlato di liste, di puntatori, non capisco perchè te ne parla...
Se ti confonde lascia perdere il mio discorso, è semplicemente cosa accade quando chiami una funziona ricorsiva.
Fai così, prendi quello che hai detto te qua ed applicalo all'albero.
l'albero astratto vero è questo:
vedi le foglie....
Io non ho mai parlato di liste, di puntatori, non capisco perchè te ne parla...
Se ti confonde lascia perdere il mio discorso, è semplicemente cosa accade quando chiami una funziona ricorsiva.
Fai così, prendi quello che hai detto te qua ed applicalo all'albero.
l'albero astratto vero è questo:
vedi le foglie....
aspetta un secondo  ...non sei stato tu a confondermi con quel codice,ma ero io che credevo fosse simile ad una lista,dove un nodo era una struttura,che aveva un campo argomento e due puntatori.Il codice altrettando mi faceva pensare la stessa cosa,essendoci una sintassi simile e valori come NULL,che associo solo alle liste...
...non sei stato tu a confondermi con quel codice,ma ero io che credevo fosse simile ad una lista,dove un nodo era una struttura,che aveva un campo argomento e due puntatori.Il codice altrettando mi faceva pensare la stessa cosa,essendoci una sintassi simile e valori come NULL,che associo solo alle liste...
comunque i tuoi esempi sono uno meglio dell'altro, ma non mi tornavano alcune cose, perchè ragionavo con i puntatori..
ps: Ho capito anche cosa significava quando dicevi ritorna indietro,nel tuo codice semplificato..
Qundi le liste non centrano niente con gli alberi??anche se si ha NULL, oppure t->qualcosa ecc..
comunque i tuoi esempi sono uno meglio dell'altro, ma non mi tornavano alcune cose, perchè ragionavo con i puntatori..
ps: Ho capito anche cosa significava quando dicevi ritorna indietro,nel tuo codice semplificato..
Qundi le liste non centrano niente con gli alberi??anche se si ha NULL, oppure t->qualcosa ecc..
"Gianni91":
Qundi le liste non centrano niente con gli alberi??anche se si ha NULL, oppure t->qualcosa ecc..
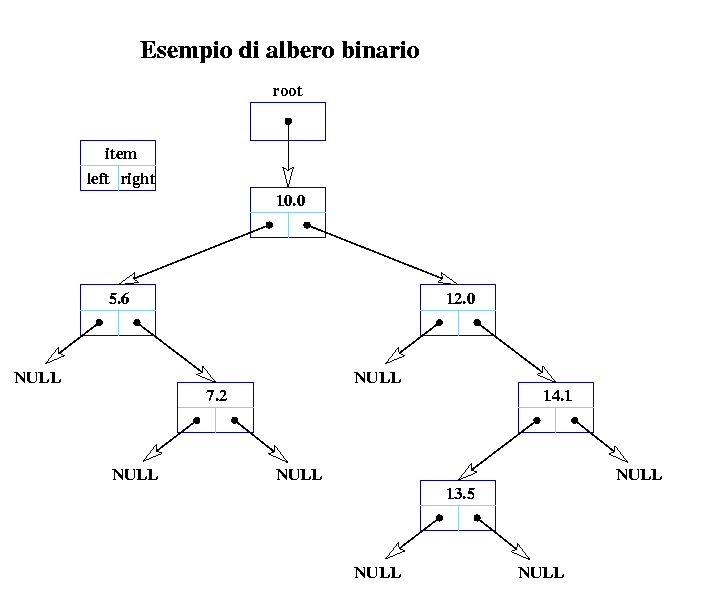
si centrano. Di solito gli alberi sono rappresentati con quella struttura dati, cioè di puntatori (vedi l'immagine), poi dipende dal linguaggio, dalle necessità...
Ma non centrano con la spiegazione che ti ho fatto io, te parlavi di un puntatore che è collegato con il "return" della chiamata di funzione, cosa che non c'entra un piffero
Io spiegavo cosa il codice faceva in "memoria".
Una cosa è applicare la funzione all'albero astratto (il disegno), un'altra è simulare l'algoritmo con la struttura "fisica" in memoria, che è rappresentata dai puntatori.
Sono diversi livelli di astrazione
"ham_burst":
Ma non centrano con la spiegazione che ti ho fatto io, te parlavi di un puntatore che è collegato con il "return" della chiamata di funzione, cosa che non c'entra un piffero
Si mi sono spiegato male...
"ham_burst":
Una cosa è applicare la funzione all'albero astratto (il disegno), un'altra è simulare l'algoritmo con la struttura "fisica" in memoria, che è rappresentata dai puntatori.
Sono diversi livelli di astrazione
Si,hai perfettamente ragione, ero io che facevo confusione..
Finalmente sono riuscito a capire come funziona la ricorsione sugli alberi
Avevo intenzione di chiedere un'altra cosa,che riguardava gli algoritmi Non deterministici...
cmq visto tutto il tempo, che mi hai concesso..
Ti chiedo solo di linkarmi(se conosci),qualcosa di interessante su questo argomento..
Grazie per tutto l'aiuto che mi hai dato.

 Accedi a tutti gli appunti
Accedi a tutti gli appunti
 Tutor AI: studia meglio e in meno tempo
Tutor AI: studia meglio e in meno tempo