[C] Compilatore e divisione

Ciao, personalmente non conosco il linguaggio assembly, ma per caso da una discussione è emerso che il compilatore per effettuare la divisione intera $D/18$ effettuasse il prodotto tra $D$ e il numero $954437177$, per poi eseguire uno shift a destra di $34$ posizioni.
Dal momento che la cosa mi incuriosiva, ho deciso di rifletterci un po' su, e la prima cosa che mi è venuta in mente per "trasformare" una divisione in una moltiplicazione è quella di moltiplicare il dividendo per l'inverso del divisore:
$D/18=1/2(D/9)=1/2(D*1/9)$
Essendo $9=(1001)_2$ ho svolto la divisione $1/9$ in binario
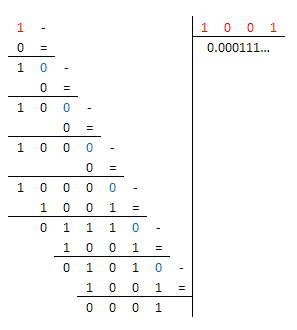
Dal momento che $1/9$ non può essere rappresentato in binario in modo esatto, ho pensato di approssimare la parte dopo la virgola in 32 bit (in modo che, ipotizzando che anche $D$ sia un intero a 32 bit, il loro prodotto possa essere espresso attraverso una variabile intera a 64 bit):
$1/9=1/(1001)_2=(0.bar(000111))_2\approx(0.000|11100011100011100011100011100011|)_2=$
$=(11100011100011100011100011100011)_2/2^(32+3)$
In definitiva quindi ottengo che la parte intera della suddetta divisione può essere calcolata come:
$[D/18]=[1/2(D*(0.bar(000111))_2)]=D*(11100011100011100011100011100011)_2$ \(\gg(32+3+1)\)
E' evidente che i $(11100011100011100011100011100011)_2=(3817748707)_(10)$ e $36$ ottenuti siano diversi dai $954437177$ e $34$ utilizzati dal compilatore, anche se utilizzando per l'approssimazione 30 bit e non 32 i numeri tornano "quasi" del tutto:
$D*((11100011100011100011100011100011)_2$ \(\gg2)\gg34=\)
\(=D*954437176\gg34\)
"Quasi" nel senso che il secondo fattore è più piccolo di un'unità rispetto a quello utilizzato dal compilatore.
-----------------------------------------------------------------------------------------------------------------------
In generale avremo quindi che
$[D/d]=D*q$ \(\gg\) $n$
con $q$ e $n$ che sono funzione di $d$.
Ovviamente affinché questo metodo sia performante i valori di $q$ e $n$ devono essere già noti; nel mio caso ho posto [inline]d_max = 100000[/inline] e ho utilizzato gli array [inline]v_q[/inline] e [inline]v_n[/inline] per contenere rispettivamente i valori di $q$ e $n$ calcolati (dalla funzione [inline]fun()[/inline] ) per valori di $d$ appartenenti all'intervallo $[1;100000]$. Quindi per esempio per accedere ai valori di $q$ e $n$ per $d = 41$ basterà accedere rispettivamente agli elementi [inline]v_q[41][/inline] e [inline]v_n[41][/inline].
Per testare il tutto ho disabilitato le ottimizzazioni del compilatore (affinché non venissero ignorati i cicli) e ho misurato i tempi necessari a calcolare [inline]N[/inline] volte una stessa divisione in diversi scenari:
- NATIVA: si riferisce alla divisione nativa del compilatore;
- OTTIMIZZATA CON ARRAY: si riferisce alla versione da me implementata con i valori di $q$ e $n$ prelevati rispettivamente dagli array [inline]v_q[/inline] e [inline]v_n[/inline]. Inoltre non ho utilizzato la funzione [inline]optimized_division()[/inline] per velocizzare il tutto evitando le varie chiamate a funzione (visto che la parola chiave [inline]inline[/inline] non sembra fare effetto);
- OTTIMIZZATA SENZA ARRAY: come sopra, ma i valori di $q$ e $n$ sono stati estratti dai due array per risparmiare sui tempi di accesso agli array.
Un altro test sulla velocità l'ho fatto misurando i tempi necessari a calcolare [inline]N[/inline] divisioni in cui il divisore è dato da [inline]rand() + 1[/inline] (che nel mio caso va bene essendo [inline]RAND_MAX < d_max[/inline] ).
Infine ho eseguito un test simile al precedente, ma questo volta non per calcolare i tempi, ma per valutare se la divisione nativa e la divisione da me implementata restituissero sempre gli stessi risultati.
Di seguito riporto il codice e l'output che ottengo lanciandolo:
A questo punto le questioni sono fondamentalmente due:
- ritenete che il compilatore utilizzi per la divisione intera un approccio simile a quello da me implementato?
Dai primi due test si evince relativamente ai tempi che [inline]OTTIMIZZATA CON ARRAY > NATIVA > OTTIMIZZATA SENZA ARRAY[/inline], il che mi fa pensare che il compilatore prelevi comunque i coefficienti da qualche parte, ma che questo prelievo sia più veloce rispetto a quello fatto dagli array globali [inline]v_q[/inline] e [inline]v_n[/inline]. Concordate sul fatto che anche il compilatore deve avere già a disposizione da qualche parte questi valori? E in tal caso dove e come ci accede?
- Dal terzo test si osserva che in alcuni casi (ossia per alcuni valori di $d$), la divisione da me implementata restituisce valori che sono più piccoli di un'unità rispetto al risultato reale. Come già ipotizzato in precedenza deve esserci qualche particolare che mi sfugge e di cui non ho tenuto conto nella fase di approssimazione; infatti se aumento i valori di $q$ di un'unità, i test fatti mi restituiscono sempre il risultato corretto. Come mai?
Dal momento che la cosa mi incuriosiva, ho deciso di rifletterci un po' su, e la prima cosa che mi è venuta in mente per "trasformare" una divisione in una moltiplicazione è quella di moltiplicare il dividendo per l'inverso del divisore:
$D/18=1/2(D/9)=1/2(D*1/9)$
Essendo $9=(1001)_2$ ho svolto la divisione $1/9$ in binario
Dal momento che $1/9$ non può essere rappresentato in binario in modo esatto, ho pensato di approssimare la parte dopo la virgola in 32 bit (in modo che, ipotizzando che anche $D$ sia un intero a 32 bit, il loro prodotto possa essere espresso attraverso una variabile intera a 64 bit):
$1/9=1/(1001)_2=(0.bar(000111))_2\approx(0.000|11100011100011100011100011100011|)_2=$
$=(11100011100011100011100011100011)_2/2^(32+3)$
In definitiva quindi ottengo che la parte intera della suddetta divisione può essere calcolata come:
$[D/18]=[1/2(D*(0.bar(000111))_2)]=D*(11100011100011100011100011100011)_2$ \(\gg(32+3+1)\)
E' evidente che i $(11100011100011100011100011100011)_2=(3817748707)_(10)$ e $36$ ottenuti siano diversi dai $954437177$ e $34$ utilizzati dal compilatore, anche se utilizzando per l'approssimazione 30 bit e non 32 i numeri tornano "quasi" del tutto:
$D*((11100011100011100011100011100011)_2$ \(\gg2)\gg34=\)
\(=D*954437176\gg34\)
"Quasi" nel senso che il secondo fattore è più piccolo di un'unità rispetto a quello utilizzato dal compilatore.
-----------------------------------------------------------------------------------------------------------------------
In generale avremo quindi che
$[D/d]=D*q$ \(\gg\) $n$
con $q$ e $n$ che sono funzione di $d$.
Ovviamente affinché questo metodo sia performante i valori di $q$ e $n$ devono essere già noti; nel mio caso ho posto [inline]d_max = 100000[/inline] e ho utilizzato gli array [inline]v_q[/inline] e [inline]v_n[/inline] per contenere rispettivamente i valori di $q$ e $n$ calcolati (dalla funzione [inline]fun()[/inline] ) per valori di $d$ appartenenti all'intervallo $[1;100000]$. Quindi per esempio per accedere ai valori di $q$ e $n$ per $d = 41$ basterà accedere rispettivamente agli elementi [inline]v_q[41][/inline] e [inline]v_n[41][/inline].
Per testare il tutto ho disabilitato le ottimizzazioni del compilatore (affinché non venissero ignorati i cicli) e ho misurato i tempi necessari a calcolare [inline]N[/inline] volte una stessa divisione in diversi scenari:
- NATIVA: si riferisce alla divisione nativa del compilatore;
- OTTIMIZZATA CON ARRAY: si riferisce alla versione da me implementata con i valori di $q$ e $n$ prelevati rispettivamente dagli array [inline]v_q[/inline] e [inline]v_n[/inline]. Inoltre non ho utilizzato la funzione [inline]optimized_division()[/inline] per velocizzare il tutto evitando le varie chiamate a funzione (visto che la parola chiave [inline]inline[/inline] non sembra fare effetto);
- OTTIMIZZATA SENZA ARRAY: come sopra, ma i valori di $q$ e $n$ sono stati estratti dai due array per risparmiare sui tempi di accesso agli array.
Un altro test sulla velocità l'ho fatto misurando i tempi necessari a calcolare [inline]N[/inline] divisioni in cui il divisore è dato da [inline]rand() + 1[/inline] (che nel mio caso va bene essendo [inline]RAND_MAX < d_max[/inline] ).
Infine ho eseguito un test simile al precedente, ma questo volta non per calcolare i tempi, ma per valutare se la divisione nativa e la divisione da me implementata restituissero sempre gli stessi risultati.
Di seguito riporto il codice e l'output che ottengo lanciandolo:
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <time.h>
#define MAX_d 100000
uint32_t v_q[MAX_d + 1];
uint32_t v_n[MAX_d + 1];
void fun(const uint32_t max_d)
{
for(uint32_t d = 2; d <= max_d; ++d)
{
uint32_t D = 1;
uint32_t d_2 = d;
uint32_t q = 0;
uint8_t n = 0;
for(; !(D & d_2); ++n, d_2 >>= 1);
if(d == d_2)
{
for(; D < d_2; ++n, D <<= 1);
for(uint8_t i = 0; i < 32; ++i)
{
q <<= 1;
if(D > d_2)
{
q |= 1;
D -= d_2;
}
D <<= 1;
}
v_q[d] = q;
v_n[d] = n;
}
else
{
v_q[d] = v_q[d_2];
v_n[d] = v_n[d_2] + n;
}
}
}
uint32_t optimized_division(const uint32_t D, const uint32_t d)
{
if(d < D)
{
return v_q[d] ? (uint64_t)D * v_q[d] >> 31 + v_n[d] : D >> v_n[d];
}
return d == D ? 1 : 0;
}
int main()
{
uint32_t D = 941787252;
uint32_t d = 36248; // <= MAX_d
fun(MAX_d);
printf("OK\n\n");
uint32_t N = 50000000;
srand(time(0));
clock_t begin;
clock_t end;
begin = clock();
for(uint32_t i = 0; i < N; ++i)
{
D / d;
}
end = clock();
printf("%ux [ %u / %u = %u ] IN %fs (NATIVA)\n", N, D, d, D / d, (double)(end - begin) / CLOCKS_PER_SEC);
begin = clock();
for(uint32_t q = v_q[d], n = v_n[d], i = 0; i < N; ++i)
{
d < D ? (q ? (uint64_t)D * q >> 31 + n : D >> n) : (d == D ? 1 : 0);
}
end = clock();
printf("%ux [ %u / %u = %u ] IN %fs (OTTIMIZZATA SENZA ARRAY)\n", N, D, d, d < D ? (v_q[d] ? (uint64_t)D * v_q[d] >> 31 + v_n[d] : D >> v_n[d]) : (d == D ? 1 : 0), (double)(end - begin) / CLOCKS_PER_SEC);
begin = clock();
for(uint32_t i = 0; i < N; ++i)
{
d < D ? (v_q[d] ? (uint64_t)D * v_q[d] >> 31 + v_n[d] : D >> v_n[d]) : (d == D ? 1 : 0);
}
end = clock();
printf("%ux [ %u / %u = %u ] IN %fs (OTTIMIZZATA CON ARRAY)\n", N, D, d, d < D ? (v_q[d] ? (uint64_t)D * v_q[d] >> 31 + v_n[d] : D >> v_n[d]) : (d == D ? 1 : 0), (double)(end - begin) / CLOCKS_PER_SEC);
begin = clock();
for(uint32_t i = 0; i < N; ++i)
{
D / (rand() + 1);
}
end = clock();
printf("\n%ux [ %u / (rand() + 1) ] IN %fs (NATIVA)\n", N, D, (double)(end - begin) / CLOCKS_PER_SEC);
begin = clock();
for(uint32_t i = 0; i < N; ++i)
{
d = rand() + 1;
d < D ? (v_q[d] ? (uint64_t)D * v_q[d] >> 31 + v_n[d] : D >> v_n[d]) : (d == D ? 1 : 0);
}
end = clock();
printf("%ux [ %u / (rand() + 1) ] IN %fs (OTTIMIZZATA CON ARRAY)\n", N, D, (double)(end - begin) / CLOCKS_PER_SEC);
printf("\n------");
for(uint32_t cont = 0, i = 0; i < N && cont < 5; ++i)
{
d = rand() + 1;
if(D / d != optimized_division(D, d))
{
++cont;
printf("\n%u / %u = %u (NATIVA)", D, d, D / d);
printf("\n%u / %u = %u (OTTIMIZZATA)\n", D, d, optimized_division(D, d));
}
}
printf("------\n");
}OK 50000000x [ 941787252 / 36248 = 25981 ] IN 0.123000s (NATIVA) 50000000x [ 941787252 / 36248 = 25981 ] IN 0.119000s (OTTIMIZZATA SENZA ARRAY) 50000000x [ 941787252 / 36248 = 25981 ] IN 0.137000s (OTTIMIZZATA CON ARRAY) 50000000x [ 941787252 / (rand() + 1) ] IN 0.732000s (NATIVA) 50000000x [ 941787252 / (rand() + 1) ] IN 0.766000s (OTTIMIZZATA CON ARRAY) ------ 941787252 / 84 = 11211753 (NATIVA) 941787252 / 84 = 11211752 (OTTIMIZZATA) 941787252 / 294 = 3203358 (NATIVA) 941787252 / 294 = 3203357 (OTTIMIZZATA) 941787252 / 252 = 3737251 (NATIVA) 941787252 / 252 = 3737250 (OTTIMIZZATA) 941787252 / 14 = 67270518 (NATIVA) 941787252 / 14 = 67270517 (OTTIMIZZATA) 941787252 / 3 = 313929084 (NATIVA) 941787252 / 3 = 313929083 (OTTIMIZZATA) ------ Process returned 0 (0x0) execution time : 1.911 s Press any key to continue.
A questo punto le questioni sono fondamentalmente due:
- ritenete che il compilatore utilizzi per la divisione intera un approccio simile a quello da me implementato?
Dai primi due test si evince relativamente ai tempi che [inline]OTTIMIZZATA CON ARRAY > NATIVA > OTTIMIZZATA SENZA ARRAY[/inline], il che mi fa pensare che il compilatore prelevi comunque i coefficienti da qualche parte, ma che questo prelievo sia più veloce rispetto a quello fatto dagli array globali [inline]v_q[/inline] e [inline]v_n[/inline]. Concordate sul fatto che anche il compilatore deve avere già a disposizione da qualche parte questi valori? E in tal caso dove e come ci accede?
- Dal terzo test si osserva che in alcuni casi (ossia per alcuni valori di $d$), la divisione da me implementata restituisce valori che sono più piccoli di un'unità rispetto al risultato reale. Come già ipotizzato in precedenza deve esserci qualche particolare che mi sfugge e di cui non ho tenuto conto nella fase di approssimazione; infatti se aumento i valori di $q$ di un'unità, i test fatti mi restituiscono sempre il risultato corretto. Come mai?
Risposte
"utente__medio":
Per il calcolo di [inline]k_max[/inline] riesco a cavarmela con una divisione intera, ma per [inline]D_max[/inline], dal momento che quel prodotto può generare un overflow, ho pensato di utilizzare il tipo [inline]double[/inline]. A tal proposito è possibile calcolare [inline]D_max[/inline] senza utilizzare variabili a virgola mobile o soluzioni troppo arzigogolate? E, visto che non ho molta esperienza con l'analisi numerica riguardante i numeri in floating point, mi chiedevo se l'utilizzo di [inline]double[/inline] in questa circostanza potesse riservare qualche "sorpresa" inaspettata.
Alla fine per il calcolo di [inline]D_max[/inline] ho lasciato perdere i [inline]double[/inline] e ho pensato ad una soluzione con gli interi.
Di seguito riprendo e integro il mio precedente post relativamente alla parte più informatica ed implementativa del problema:
Questo invece il codice che ne deriva con relativo output che mostra i risultati di alcuni test:
Eventuali migliorie e/o osservazioni sono ben accette.

 Accedi a tutti gli appunti
Accedi a tutti gli appunti
 Tutor AI: studia meglio e in meno tempo
Tutor AI: studia meglio e in meno tempo